Solution - A Multiplicity of Models
Contents
Solution - A Multiplicity of Models¶
We haven’t really talked too much about specific models or algorithms, that is something you can study on your own, but a warning – that liteature is extensive, so I’d suggest starting with YouTube videos.
In general you might approach a given classification or regression problem with a number of different possible models to determine which is the most useful for your purposes (e.g., most accurate, least biased, etc.). A few potential models (not exhaustive) are listed below based on the type of problem they can solve:
Classification: Logistic Regression, K Nearest Neighbors, Support Vector Machines, Random Forest, Neural Networks
Regression: Linear Regression, Polynomial Regression, Stochastic Gradient Descent, Support Vector Machines, Random Forest, Neural Networks
In this notebook, you will work with synthesized data to understand the workflow for using and comparing classifiers. Along the way, we will introduce new models, but only link to videos that explain what they do.
0. Today’s Initial Imports¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification, make_circles
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score, ShuffleSplit
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, roc_auc_score, accuracy_score, roc_auc_score
%matplotlib inline
1. Example: Validating a Logistic Regression Model¶
We will start with a Logistic Regression Model and synthesized data.
[Logistic Regression Explained] (No need to watch in class.)
By reviewing and working with this example, you should be able to identify and explain the different ways in which we are validating the Logisitc Regression model.
1.1 Making classification data¶
We start by making the data using the make_classification() method. I will pick 1000 samples with 20 features; only 4 of them will be informative about the 2 classes. What make_classification() returns are the data (the features for the model) and the class labels (the 1 or 0). For simplicity and familiarity, I convert them both to pandas data frames as this is typically what you would do with data you read in.
## Parameters for making data
N_samples = 1000
N_features = 20
N_informative = 4
N_classes = 2
## Make up some data for classification
X, y = make_classification(n_samples = N_samples,
n_features = N_features,
n_informative = N_informative,
n_classes = N_classes)
## Store the data in a data frame
feature_list = []
for feature in np.arange(N_features):
feature_list.append('feature_'+str(feature))
features = pd.DataFrame(X, columns=feature_list)
classes = pd.DataFrame(y, columns=['label'])
We can check the .head() of both data frames to make sure we know what we imported.
features.head()
| feature_0 | feature_1 | feature_2 | feature_3 | feature_4 | feature_5 | feature_6 | feature_7 | feature_8 | feature_9 | feature_10 | feature_11 | feature_12 | feature_13 | feature_14 | feature_15 | feature_16 | feature_17 | feature_18 | feature_19 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.612694 | -0.103132 | -0.267346 | 0.153512 | 0.516020 | 1.251561 | 0.848281 | 5.009086 | -1.363851 | 0.776745 | -0.439468 | 0.050744 | 1.317167 | -0.170907 | -1.348628 | -3.181531 | 0.888695 | 2.701562 | 3.315473 | -0.287589 |
| 1 | -0.725912 | 1.997657 | 0.074594 | -2.577062 | -0.232693 | -1.881299 | -0.284693 | 1.363553 | 1.100933 | -0.922893 | 0.720922 | -2.065911 | -0.102098 | 0.211984 | -0.801021 | -1.387583 | -0.905420 | 1.405053 | -0.175970 | -0.075030 |
| 2 | 1.192186 | 0.335299 | -0.157549 | -0.004746 | 1.369081 | -1.357544 | -1.641488 | 0.992889 | -0.065464 | 0.037287 | 0.480859 | 0.681286 | 0.052300 | 0.836286 | 0.151800 | -0.549929 | 1.161110 | 0.687438 | 1.756267 | 0.393012 |
| 3 | -1.639626 | -0.448213 | -0.539223 | -0.418453 | 0.711005 | -1.779812 | -0.648124 | 0.528442 | 0.578592 | 1.000328 | -1.524049 | 1.582335 | 0.165979 | 1.084902 | -0.863999 | -0.665511 | -0.566369 | 0.405010 | -1.509371 | 0.718972 |
| 4 | 1.545687 | -1.445203 | -0.781868 | 0.824983 | 0.773158 | 1.097341 | 0.108031 | 0.087304 | 2.005362 | -0.799365 | -0.227030 | -0.330740 | -0.024312 | 1.386112 | -0.062559 | 0.292620 | 2.614725 | -0.115821 | 1.601066 | 1.086189 |
classes.head()
| label | |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
1.2 Plotting Feature Spaces¶
We’ve found that looking at the classes in some feature subspace has been helpful in seeing if there are subspaces where the classes are more separated. We do this so frequently, it is worth having a little piece of code to do that. I’ve written one below.
def PlotFeatureSpace(x1,x2,c):
'''From a Data Series, PlotFeatureSpace creates a
scatter plot of two features and colors the dots
using the classes. The figure labels are the names
of each passed column of the Data Series.'''
plt.figure()
plt.scatter(x1, x2, c=c)
plt.xlabel(x1.name);
plt.ylabel(x2.name);
✎ Do this: Using PlotFeatureSpace(), try to find at least two possible features that might be important to the model. That is, can you find two features that seperate the classes well? I’ve given an example call below.
## Parameters for PlotFutureSpace
x = "feature_1"
y = "feature_2"
c = classes['label']
PlotFeatureSpace(features[x], features[y], c)
✎ Do this: Which two features did you find? Keep note here!
If you rerun the data creation process, the same two features might no longer be useful.
✎ Do this: Erase this and write here.
1.3 A Logistic Regression Model¶
As we did with KNN, we will train and test a classification model. This time it will be a Logitstic Regression model. We will first use the confusion matrix to determine how things are going. I’ve written to code below to split the data, create the model, fit it, and predict the classes of the test data.
## Split the data
x_train, x_test, y_train, y_test = train_test_split(features, classes)
## Create an instance of the model (LR with no regularization)
model = LogisticRegression(penalty='none')
## Fit the model to the training data
model.fit(x_train, y_train['label'])
## Use that model to predict test outcomes
y_pred = model.predict(x_test)
## Compare the real outcomes to the predicted outcomes
print(confusion_matrix(y_test, y_pred))
[[106 21]
[ 19 104]]
1.3.1 The Metric Zoo¶
There are many different ways to use the confusion matrix to determine different qualities of your classifier. Accuracy, the number of true positives and negatives comapred to all predictions is just one of these metrics. There’s a lot of them! [Wikipedia article on evaluation metrics]
Two of the more important ones are the accuracy (as we’ve used before) and the f1-score (closer to 1 is better). The sklearn toolkit has all these built-in, but one tool that is at the ready is classification_report(), which gives the accuracy, the f-1 score, as well as the precision and recall – two other common metrics for evaluation.
Once we have predicted class labels, then we can use classification_report. Both the confusion_matrix and classification_report can be used with any of sklearn’s classifiers.
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.85 0.83 0.84 127
1 0.83 0.85 0.84 123
accuracy 0.84 250
macro avg 0.84 0.84 0.84 250
weighted avg 0.84 0.84 0.84 250
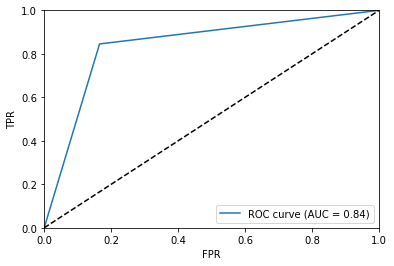
1.4 AUC and the ROC Curve¶
The Receiver Operator Characteristic (ROC) Curve and the associated Area Under the Curve (AUC) are additional tools that help us validate our model. Fortunately, sklearn has roc_curve, that will return to quantities needed to plot this curve. The AUC can also be determined using the built in roc_auc_score() method.
Below I wrote a little bit of code to plot the ROC curve and compute the AUC for this model.
Again, both of the tools are available for any classifier model.
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (AUC = %0.2f)' % roc_auc_score(y_test,y_pred))
plt.plot([0, 1], [0, 1], c='k', linestyle='--')
plt.axis([0, 1, 0, 1])
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.legend(loc="lower right")
<matplotlib.legend.Legend at 0x7fa6a00ce790>
1.5 Model Specific Tools - Logistic Regression¶
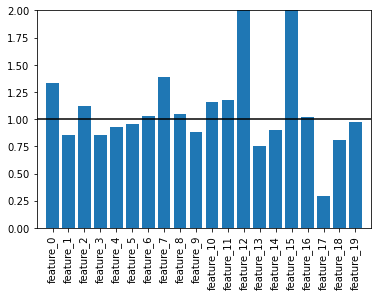
A LR model uses a transformed linear model to fit the data. It predicts numerical weights for each feature in the data. Those numerical weights can be converted to odds ratio by exponentiating them:
\(odds_i = \exp(\beta_i)\)
where \(\beta_i\) is the numerical weight for the \(i\)th feature determined by the model. In sklearn speak, these would be “coefficients” of the model; coef_ in code (and yes with the trailing underscore). The nice thing about LR is that these coefficients are typically interpretable. That is if the odds of a feature is close to one then that feature has virtually no effect on the model. On the other hand, if a feature is much larger than one, we find that might contribute a lot to the model.
In this case, we’d expect that feature to be useful in separating the two class labels. That is why you predicted two features earlier!
Below I wrote a little code to find those odds ratios.
## Extract model coefficeints
print("Model Coefficients:", model.coef_)
## Compute odds ratios from model coefficients
odds = np.exp(model.coef_.ravel())
print("Odds Ratios:", odds)
Model Coefficients: [[ 0.28648194 -0.15926342 0.1134972 -0.16133451 -0.07551187 -0.04623385
0.02590664 0.32990226 0.05113671 -0.12060272 0.14801497 0.16053251
0.73469794 -0.28129667 -0.10123816 0.77144284 0.01855754 -1.2364377
-0.21532248 -0.02769494]]
Odds Ratios: [1.33173411 0.85277169 1.12018875 0.85100735 0.92726872 0.95481865
1.02624514 1.39083219 1.05246676 0.88638603 1.15953026 1.17413594
2.08485214 0.75480437 0.90371778 2.1628847 1.0187308 0.29041693
0.80628139 0.97268504]
✎ Do this: Make a bar plot of the odds ratios. Which ones appear to contribute to the model? Are any of them the two featurs you found earlier? You can use Plot_Feature_Space() to confirm.
## your code here
### ANSWER ####
plt.figure()
plt.bar(np.arange(0,20), odds)
plt.xticks(ticks=np.arange(0,20),
labels=features.columns,
rotation=90)
plt.hlines(1,-1,20, 'k')
plt.axis([-1, 20, 0, 2])
PlotFeatureSpace(features["feature_2"], features["feature_11"], classes['label'])
1.5 Monte Carlo Validation¶
One of the important things about machine learning is that it often relies on the randomness of the draw of training and testing sets. As a result, any one time the model is run you are working with a particualr choice of data for training and testing. Thus, there’s a problem in reporting the results of a single model because it depends on the curiousities of what was drawn in the first place!
One of the ways we validate the model we have used is to determine how representative our one run is compared to a large number of runs. Ideally, we’d like to know what the disitrbution of possible results could be. That allows us to put some error bounds on the estimated model parameters and to explain the confidence we have in our approach and results.
There’s two main types of validation, although many others exist and there’s nuance inside of each:
Cross-Validation: The algorithm slices the data in N bins. Then it treats each bin in turn as a test set using the reamining N-1 bins as the training data. This approach and modifications to it are part of
sklearn. Cross Validation DocumentationMonte Carlo Validation: This is relatively simple as you simply repslit the data and run the model again and collect the results. This is the approach we will use in this notebook.
Below, I wrote a short function that splits the data, creates the model, fits it, and returns the evaluation metrics including the model weights. The lines below runs it.
def RunLR(features, classes, penalty='none'):
'''RunLR runs a logisitic regression model with
default splitting. It returns evalaution metrics including
accuracy, auc, and the model coefficients.'''
x_train, x_test, y_train, y_test = train_test_split(features, classes)
LR = LogisticRegression(penalty=penalty)
LR.fit(x_train, y_train)
y_pred = LR.predict(x_test)
return accuracy_score(y_test, y_pred), roc_auc_score(y_test, y_pred), LR.coef_
acc, auc, model_coefs = RunLR(features, classes['label'])
print("Accuracy: ", acc)
print("AUC:", auc)
print("Coefs:", model_coefs)
Accuracy: 0.88
AUC: 0.880097304910057
Coefs: [[ 0.25439842 -0.07382031 0.09365829 -0.05001636 -0.03492446 -0.06413302
0.03060601 0.30467016 0.05482755 -0.12068881 0.05412923 0.31332987
0.69180165 -0.10037106 -0.06209718 0.71336808 -0.01739148 -1.14956494
-0.19449412 0.00931756]]
✎ Do this: Write a loop that does Monte Carlo Validation with 100 trials using RunLR(). Make sure to store the accuracy and auc each time the loop runs - you will want to know how these are distributed.
You can also try to store the model coefficients, but that isn’t necessary to understand what we are trying to do. And it might lead to shape mismatch issues that aren’t worth debugging right now
## Your code here
### ANSWER ###
N = 100
acc = 0
auc = 0
acc_array = np.empty((0,N), float)
auc_array = np.empty((0,N), float)
coef_array = np.empty((N,20), float)
for i in range(N):
acc, auc, coefs = RunLR(features, classes['label'])
acc_array = np.append(acc_array,acc)
auc_array = np.append(auc_array,auc)
coef_array = np.concatenate((coef_array, coefs), axis=0)
✎ Do this: Now that you have the distribution of accuracy scores and auc, let’s compute the mean, standard deviation, and plot them as historgrams. Do you notice anything about the shape of the histograms?
## your code here
### ANSWER ###
mean_acc = np.mean(acc_array)
std_acc = np.std(acc_array)
mean_auc = np.mean(auc_array)
std_auc = np.std(auc_array)
coef_array
mean_coef = np.mean(coef_array, axis=0)
std_coef = np.std(coef_array, axis=0)
plt.figure()
plt.hist(acc_array)
print("Mean Accuracy:", mean_acc, "+/-", std_acc)
plt.ylabel('Counts')
plt.xlabel('ACC')
plt.figure()
plt.hist(auc_array)
print("Mean AUC:", mean_auc, "+/-", std_auc)
plt.ylabel('Counts')
plt.xlabel('AUC')
plt.figure()
plt.errorbar(np.arange(20), np.exp(mean_coef), yerr=np.exp(std_coef)/np.sqrt(len(std_coef)), fmt="s")
plt.hlines(1, -1, 20, 'k')
plt.axis([-1,20,0,2])
plt.xticks(ticks=np.arange(0,20),
labels=features.columns,
rotation=90)
plt.xlabel('Feature Number')
plt.ylabel('Odds Ratio')
Mean Accuracy: 0.8376399999999999 +/- 0.01888148299260415
Mean AUC: 0.8379295179018895 +/- 0.01904418070282785
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/numpy/core/_methods.py:232: RuntimeWarning: overflow encountered in multiply
x = um.multiply(x, x, out=x)
<ipython-input-18-41a35c4ff664>:26: RuntimeWarning: overflow encountered in exp
plt.errorbar(np.arange(20), np.exp(mean_coef), yerr=np.exp(std_coef)/np.sqrt(len(std_coef)), fmt="s")
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/matplotlib/axes/_axes.py:3411: RuntimeWarning: invalid value encountered in double_scalars
low = [v if lo else v - e for v, e, lo in zip(data, a, lolims)]
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/numpy/core/_asarray.py:102: UserWarning: Warning: converting a masked element to nan.
return array(a, dtype, copy=False, order=order)
Text(0, 0.5, 'Odds Ratio')



2. Parameter Tuning¶
Great! Now that we have seen how we can explore our confidence in the model we created, we can now determine if indeed we have the best logisitc regression model we could have. There’s a number of parameters that the logisitic regression method can take when you create an instance. Each of them control different aspects of how the model fits.
For our purposes, we will just explore if it was ok to use no penalization. Penalization is how a logistic regression model might control for variables that don’t matter too much. Penalization tends to shrink model coefficients towards zero if they are small, so it’s clear what contributes and what doesn’t.
To do a little paramter testing we will use GridSearchCV(). The method basically wraps any class to a classifier (or regressor) and then lets you tell it, please try all these potential versions. For example, we have four choices of penalization l1, l2, elasticnet (which is l1 and l2 at the same time), and none (which we have used all along). So we can test all four models simulatneously to see which is the best.
I wrote a little code that does that. Notice that parameters is basically a set where penalty is the variable for the model and the list that follows indicates that type of penalty to try. Once you run .fit() the models start being built. Notice combinations of parameters that can’t work together will throw warnings (this is normal, but you should chck other warnings!).
parameters = [
{'penalty': ['l1', 'l2', 'elasticnet', 'none']},
]
LR_tuned = LogisticRegression()
clf = GridSearchCV(LR_tuned, parameters)
clf.fit(features, classes['label'])
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_search.py:918: UserWarning: One or more of the test scores are non-finite: [ nan 0.842 nan 0.841]
warnings.warn(
GridSearchCV(estimator=LogisticRegression(),
param_grid=[{'penalty': ['l1', 'l2', 'elasticnet', 'none']}])
At the end of all this, we get call back with the parameter grid we created. Notice that if we had another parameter to set, GridSearchCV will try to run all parameter combinations. So that each new parameter is multiplicative leading to many models quite fast. So be careful here!
For example, consider we had three paramters, one that had two settings, one with three, and one with five. If you call a grid search with these paramters, you will be asking sklearn to create an run 2x3x5 models (30 models). If you have another parameter you want to try that has another 4 settings, you are up to 120 models!
2.1 Results of a Grid Search¶
In any event, after running this, we can find the best_estimator_ and the best_score_. The best_estimator is the call you should use for the best model tested. If any settings are the default, they will not appear in the parentheses. The best_score_ is the accuracy of that model. Of course, you can get more details (like above) if you choose that best model and run it through Monte Carlo validation.
print(clf.best_estimator_)
print(clf.best_score_)
LogisticRegression()
0.842
2.2 What about other classifiers?¶
There are many other classifers we can try on the same problem to see how well they do. There’s many out there and there’s lots of nuance to understand about each if you are going to use them. We will use K Nearest Neighbors, Supprt Vector Machines, and a Random Forest Classifier. To learn more about each, I’d suggest these videos:
Let’s import the necessary libraries and test things with KNN. Then you can write code for the Support Vector Machine, and the Random Forest.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
2.2.1 KNN¶
As we did previously we can vary the number of neighbors from the default of 5 (always good to know the defaults of the models you are calling). But this time we will use GridSearchCV. I’ve written the code to do this below. You can adapt it for other models in the next sections as you like.
## Sweep through 2 to 20 neighbors
parameters = [
{'n_neighbors': np.arange(2,21)}
]
## Create the Grid Search and fit it
KNN_tuned = KNeighborsClassifier()
clf = GridSearchCV(KNN_tuned, parameters)
clf.fit(features, classes['label'])
## Determine the best estimator
BestKNN = clf.best_estimator_
print(BestKNN)
print(clf.best_score_)
KNeighborsClassifier(n_neighbors=7)
0.9110000000000001
We can now use the best model to do Monte Carlo Validation and plot the distributions.
def RunKNN(features, classes):
x_train, x_test, y_train, y_test = train_test_split(features, classes)
KNN = BestKNN
KNN.fit(x_train, y_train)
y_pred = KNN.predict(x_test)
return accuracy_score(y_test, y_pred), roc_auc_score(y_test, y_pred)
RunKNN(features, classes['label'])
(0.912, 0.9116380695328065)
N = 300
acc = 0
auc = 0
acc_array = np.empty((0,N), float)
auc_array = np.empty((0,N), float)
for i in range(N):
acc, auc = RunKNN(features, classes['label'])
acc_array = np.append(acc_array,acc)
auc_array = np.append(auc_array,auc)
mean_acc = np.mean(acc_array)
std_acc = np.std(acc_array)
mean_auc = np.mean(auc_array)
std_auc = np.std(auc_array)
plt.figure()
plt.hist(acc_array)
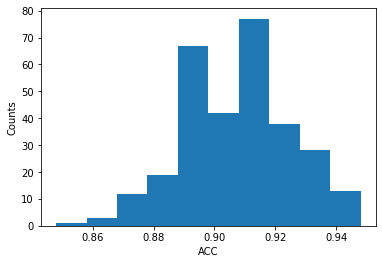
print("Mean Accuracy:", mean_acc, "+/-", std_acc)
plt.ylabel('Counts')
plt.xlabel('ACC')
plt.figure()
plt.hist(auc_array)
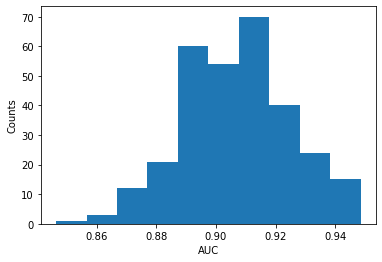
print("Mean AUC:", mean_auc, "+/-", std_auc)
plt.ylabel('Counts')
plt.xlabel('AUC')
Mean Accuracy: 0.90656 +/- 0.01794676572533336
Mean AUC: 0.9068908227569153 +/- 0.01789355995825222
Text(0.5, 0, 'AUC')
2.2.2 LinearSVC¶
✎ Do this: For the LinearSVC() model, repeat the work above to determine the distribution of accuracies and aucs for the model. Use GridSearchCV() to vary the C parameter and find the best model. Linear SVC Documentation
### your code here
### ANSWER ###
parameters = [
{'C': [0.001, 0.01, 0.1, 1, 10]}
]
SVM_tuned = LinearSVC(max_iter=50000)
clf = GridSearchCV(SVM_tuned, parameters)
clf.fit(features, classes['label'])
BestSVM = clf.best_estimator_
print(BestSVM)
print(clf.best_score_)
LinearSVC(C=1, max_iter=50000)
0.8400000000000001
### ANSWER ###
def RunLinSVC(features, classes):
x_train, x_test, y_train, y_test = train_test_split(features, classes)
SVM = BestSVM
SVM.fit(x_train, y_train)
y_pred = SVM.predict(x_test)
return accuracy_score(y_test, y_pred), roc_auc_score(y_test, y_pred)
RunLinSVC(features, classes['label'])
(0.824, 0.8243589743589743)
### ANSWER ###
N = 300
acc = 0
auc = 0
acc_array = np.empty((0,N), float)
auc_array = np.empty((0,N), float)
for i in range(N):
acc, auc = RunLinSVC(features, classes['label'])
acc_array = np.append(acc_array,acc)
auc_array = np.append(auc_array,auc)
mean_acc = np.mean(acc_array)
std_acc = np.std(acc_array)
mean_auc = np.mean(auc_array)
std_auc = np.std(auc_array)
plt.figure()
plt.hist(acc_array)
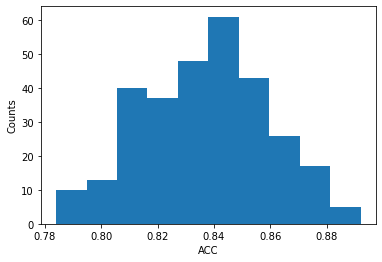
print("Mean Accuracy:", mean_acc, "+/-", std_acc)
plt.ylabel('Counts')
plt.xlabel('ACC')
plt.figure()
plt.hist(auc_array)
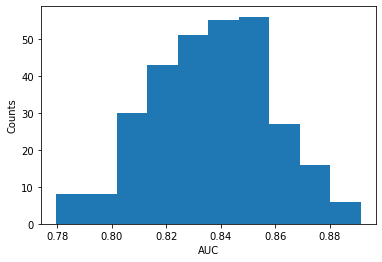
print("Mean AUC:", mean_auc, "+/-", std_auc)
plt.ylabel('Counts')
plt.xlabel('AUC')
Mean Accuracy: 0.8366533333333334 +/- 0.021953887026118068
Mean AUC: 0.8368508073669565 +/- 0.021975315690476994
Text(0.5, 0, 'AUC')
2.2.3 Random Forest¶
✎ Do this: For the RandomForestClassifier() model, repeat the work above to determine the distribution of accuracies and aucs for the model. Use GridSearchCV() to vary the n_estimators parameter and find the best model. Random Forest Documentation
## your code here
### ANSWER ####
parameters = [
{'n_estimators': [10, 50, 100, 200]},
{'criterion' : ['gini', 'entropy']},
{'max_features': ['auto', 'sqrt', 'log2']}
]
RF_tuned = RandomForestClassifier()
clf = GridSearchCV(RF_tuned, parameters)
clf.fit(features, classes['label'])
BestRF = clf.best_estimator_
print(BestRF)
print(clf.best_score_)
RandomForestClassifier(max_features='sqrt')
0.9359999999999999
### ANSWER ####
def RunRF(features, classes):
x_train, x_test, y_train, y_test = train_test_split(features, classes)
RF = BestRF
RF.fit(x_train, y_train)
y_pred = RF.predict(x_test)
return accuracy_score(y_test, y_pred), roc_auc_score(y_test, y_pred)
RunRF(features, classes['label'])
(0.944, 0.9444551220449741)
### ANSWER ####
N = 300
acc = 0
auc = 0
acc_array = np.empty((0,N), float)
auc_array = np.empty((0,N), float)
for i in range(N):
acc, auc = RunRF(features, classes['label'])
acc_array = np.append(acc_array,acc)
auc_array = np.append(auc_array,auc)
mean_acc = np.mean(acc_array)
std_acc = np.std(acc_array)
mean_auc = np.mean(auc_array)
std_auc = np.std(auc_array)
plt.figure()
plt.hist(acc_array)
print("Mean Accuracy:", mean_acc, "+/-", std_acc)
plt.ylabel('Counts')
plt.xlabel('ACC')
plt.figure()
plt.hist(auc_array)
print("Mean AUC:", mean_auc, "+/-", std_auc)
plt.ylabel('Counts')
plt.xlabel('AUC')
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-32-36993ebb1aba> in <module>
8 for i in range(N):
9
---> 10 acc, auc = RunRF(features, classes['label'])
11 acc_array = np.append(acc_array,acc)
12 auc_array = np.append(auc_array,auc)
<ipython-input-31-06de012cb42f> in RunRF(features, classes)
4 x_train, x_test, y_train, y_test = train_test_split(features, classes)
5 RF = BestRF
----> 6 RF.fit(x_train, y_train)
7 y_pred = RF.predict(x_test)
8
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/ensemble/_forest.py in fit(self, X, y, sample_weight)
385 # parallel_backend contexts set at a higher level,
386 # since correctness does not rely on using threads.
--> 387 trees = Parallel(n_jobs=self.n_jobs, verbose=self.verbose,
388 **_joblib_parallel_args(prefer='threads'))(
389 delayed(_parallel_build_trees)(
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/parallel.py in __call__(self, iterable)
1042 self._iterating = self._original_iterator is not None
1043
-> 1044 while self.dispatch_one_batch(iterator):
1045 pass
1046
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/parallel.py in dispatch_one_batch(self, iterator)
857 return False
858 else:
--> 859 self._dispatch(tasks)
860 return True
861
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/parallel.py in _dispatch(self, batch)
775 with self._lock:
776 job_idx = len(self._jobs)
--> 777 job = self._backend.apply_async(batch, callback=cb)
778 # A job can complete so quickly than its callback is
779 # called before we get here, causing self._jobs to
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/_parallel_backends.py in apply_async(self, func, callback)
206 def apply_async(self, func, callback=None):
207 """Schedule a func to be run"""
--> 208 result = ImmediateResult(func)
209 if callback:
210 callback(result)
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/_parallel_backends.py in __init__(self, batch)
570 # Don't delay the application, to avoid keeping the input
571 # arguments in memory
--> 572 self.results = batch()
573
574 def get(self):
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/parallel.py in __call__(self)
260 # change the default number of processes to -1
261 with parallel_backend(self._backend, n_jobs=self._n_jobs):
--> 262 return [func(*args, **kwargs)
263 for func, args, kwargs in self.items]
264
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/joblib/parallel.py in <listcomp>(.0)
260 # change the default number of processes to -1
261 with parallel_backend(self._backend, n_jobs=self._n_jobs):
--> 262 return [func(*args, **kwargs)
263 for func, args, kwargs in self.items]
264
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/utils/fixes.py in __call__(self, *args, **kwargs)
220 def __call__(self, *args, **kwargs):
221 with config_context(**self.config):
--> 222 return self.function(*args, **kwargs)
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/ensemble/_forest.py in _parallel_build_trees(tree, forest, X, y, sample_weight, tree_idx, n_trees, verbose, class_weight, n_samples_bootstrap)
167 indices=indices)
168
--> 169 tree.fit(X, y, sample_weight=curr_sample_weight, check_input=False)
170 else:
171 tree.fit(X, y, sample_weight=sample_weight, check_input=False)
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/tree/_classes.py in fit(self, X, y, sample_weight, check_input, X_idx_sorted)
896 """
897
--> 898 super().fit(
899 X, y,
900 sample_weight=sample_weight,
~/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/tree/_classes.py in fit(self, X, y, sample_weight, check_input, X_idx_sorted)
387 min_impurity_split)
388
--> 389 builder.build(self.tree_, X, y, sample_weight)
390
391 if self.n_outputs_ == 1 and is_classifier(self):
KeyboardInterrupt:
3. What about other kinds of data?¶
Many times it is important to know the strucutre of your data, hence plotting feature spaces. Sometimes the models you are using might be incompatible with the structure of your data. Some models try to draw lines to separate, some draw curves, some are more emergent. Let’s test this out with a ciruclar data set where we can clearly see the separation. Below, we create some data and store the values in data frames.
X, y = make_circles(n_samples = 500)
loc = pd.DataFrame(X, columns=['x1','x2'])
label = pd.DataFrame(y, columns=['y'])
loc.head()
| x1 | x2 | |
|---|---|---|
| 0 | -0.968583 | -0.248690 |
| 1 | 0.658826 | -0.453815 |
| 2 | 0.208673 | 0.772305 |
| 3 | -0.535827 | -0.844328 |
| 4 | -0.992115 | 0.125333 |
label.head()
| y | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
3.1 Plot it!¶
Let’s plot this data to see why we might not expect the same results as we had found for the previous case.
plt.figure(figsize=(5,5))
plt.scatter(loc['x1'], loc['x2'], c=label['y'])
plt.xlabel('x1')
plt.ylabel('x2')
Text(0, 0.5, 'x2')

It is really easy to see in the figure above that we have two clearly separated classes. Let’s fire up the Logisitic Regression model and see what it can find.
parameters = [
{'penalty': ['l1', 'l2', 'elasticnet', 'none']},
]
LR_tuned = LogisticRegression()
clf = GridSearchCV(LR_tuned, parameters)
clf.fit(loc, label['y'])
LRBest = clf.best_estimator_
print(LRBest)
print(clf.best_score_)
LogisticRegression()
0.43000000000000005
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py:610: FitFailedWarning: Estimator fit failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_validation.py", line 593, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 1306, in fit
solver = _check_solver(self.solver, self.penalty, self.dual)
File "/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/linear_model/_logistic.py", line 443, in _check_solver
raise ValueError("Solver %s supports only 'l2' or 'none' penalties, "
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties, got elasticnet penalty.
warnings.warn("Estimator fit failed. The score on this train-test"
/Users/caballero/opt/anaconda3/envs/ml-short-course/lib/python3.9/site-packages/sklearn/model_selection/_search.py:918: UserWarning: One or more of the test scores are non-finite: [ nan 0.43 nan 0.43]
warnings.warn(
3.2 Time to try other models¶
It appears the the logistic regression does pretty poorly. That is because logistic regression is not good with nonlinear problems. It is a linear model, so it’s hard for it to deal with things like circles!
✎ Do this: Test the SVC, KNN, and RF models on these data. Use GridSearchCV() to find the best model for each. How do the accuracies compare? Which might you use to work more on this problem? No need to plot disitrbutions for this, you can do that later if you like.
### your code here
### ANSWER ###
parameters = [
{'C': [0.001, 0.01, 0.1, 1, 10]}
]
SVM_tuned = LinearSVC(max_iter=50000)
clf = GridSearchCV(SVM_tuned, parameters)
clf.fit(loc, label['y'])
BestSVM = clf.best_estimator_
print(BestSVM)
print(clf.best_score_)
LinearSVC(C=0.001, max_iter=50000)
0.43000000000000005
### ANSWER ###
parameters = [
{'n_estimators': [10, 50, 100, 200]},
{'criterion' : ['gini', 'entropy']},
{'max_features': ['auto', 'sqrt', 'log2']}
]
RF_tuned = RandomForestClassifier()
clf = GridSearchCV(RF_tuned, parameters)
clf.fit(loc, label['y'])
BestRF = clf.best_estimator_
print(BestRF)
print(clf.best_score_)
RandomForestClassifier()
0.99
### ANSWER ###
parameters = [
{'n_neighbors': np.arange(2,21)}
]
KNN_tuned = KNeighborsClassifier()
clf = GridSearchCV(KNN_tuned, parameters)
clf.fit(loc, label['y'])
BestKNN = clf.best_estimator_
print(BestKNN)
print(clf.best_score_)
KNeighborsClassifier(n_neighbors=2)
1.0
3.3 Let’s make the data a bit messier.¶
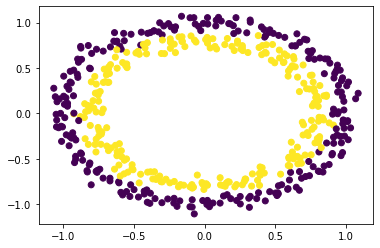
You probably found that one model worked perfectly. We can add a little noice to make things more interesting.
X, y = make_circles(n_samples = 500, noise = 0.05)
loc = pd.DataFrame(X, columns=['x1','x2'])
label = pd.DataFrame(y, columns=['y'])
plt.scatter(loc['x1'], loc['x2'], c=label['y'])
<matplotlib.collections.PathCollection at 0x7f9d18a5c790>
3.4 Try to find the best model for this data¶
✎ Do this: Test the LR, SVC, KNN, and RF models on these data. Use GridSearchCV() to find the best model for each. How do the accuracies compare? Which might you use to work more on this problem? No need to plot disitrbutions for this, you can do that later if you like.
## your code here
### ANSWER ###
parameters = [
{'n_neighbors': np.arange(2,21)}
]
KNN_tuned = KNeighborsClassifier()
clf = GridSearchCV(KNN_tuned, parameters)
clf.fit(loc, label['y'])
BestKNN = clf.best_estimator_
print(BestKNN)
print(clf.best_score_)
KNeighborsClassifier(n_neighbors=7)
0.9720000000000001
### ANSWER ###
parameters = [
{'n_estimators': [10, 50, 100, 200]},
{'criterion' : ['gini', 'entropy']},
{'max_features': ['auto', 'sqrt', 'log2']}
]
RF_tuned = RandomForestClassifier()
clf = GridSearchCV(RF_tuned, parameters)
clf.fit(loc, label['y'])
BestRF = clf.best_estimator_
print(BestRF)
print(clf.best_score_)
RandomForestClassifier(criterion='entropy')
0.942
### ANSWER ###
parameters = [
{'C': [0.001, 0.01, 0.1, 1, 10]}
]
RBF_tuned = SVC(kernel='rbf')
clf = GridSearchCV(RBF_tuned, parameters)
clf.fit(loc, label['y'])
BestRBF = clf.best_estimator_
print(BestRBF)
print(clf.best_score_)
SVC(C=1)
0.9799999999999999